A major task of every person I know from working in research is to hold presentations. Whether you go to a conference, give presentations in doctoral consortia or lecture a course: self-speaking presentations are important for your career. So are the slides and pictures you choose to transfer your views and perspectives. In the following I give a brief overview about the sources I use regularly for images and illustrations within my lectures, seminars and web projects. Upgrading my Lecture Slides weiterlesen →
Ich habe gerade das Bild von meinem knappen Sieg bei #GameOfThrones von Freitag bekommen. Danke Jochen, dass du das Schlachtfeld noch einmal so schön illustriert hast.
House Greyjoy, cc-by-sa A Wiki of Ice and Fire user Sergio Tavel.
Für alle, die sich das Spiel in den Spieleschrank zu legen wollen, fasse ich meine Eindrücke im folgenden zusammen:
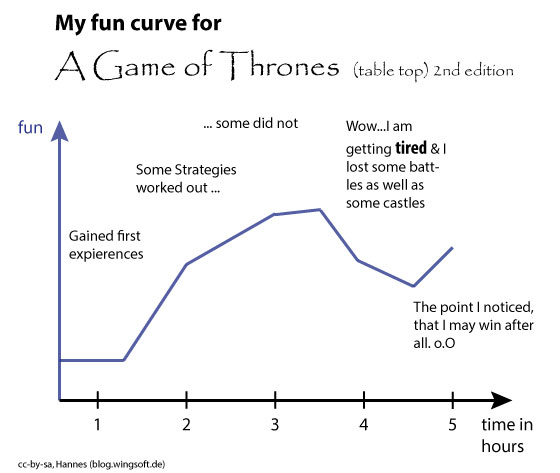
1. Wir haben mit 6 Personen knapp fünf Stunden gespielt. Davon verwendeten wir knapp 45 Minuten für das Regelwerk. Die ersten 3 Stunden waren auch echt lustig, ab dann grenzte es zunehmend an Arbeit. (siehe Illustration 1)
In einer meiner Übungen erkläre ich den Studierenden, was es mit diesem Internet auf sich hat. Ich vertiefe darin unter anderem das Themengebiet Web 2.0 / Enterprise 2.0. Nebenbei sensibilisiere ich dann auch gleich für informatisch relevante Fragestellungen. Eine der interessantesten Fragen ist sicherlich: Wie finde ich eigentlich relevante Informationen?
Das ist gar nicht so einfach zu beantworten und darüber zerbrechen sich in einer Welt, in der Daten und Informationen einem potenziellen Wachstum unterlegen, viele Menschen den Kopf. Zwei dieser Köpfe waren die beiden Gründer von Google, Sergei Brin und Larry Page. Man mag über Google heute denken, was man mag, aber die Anwendung des PageRank-Algorithmus hat das Web revolutioniert.
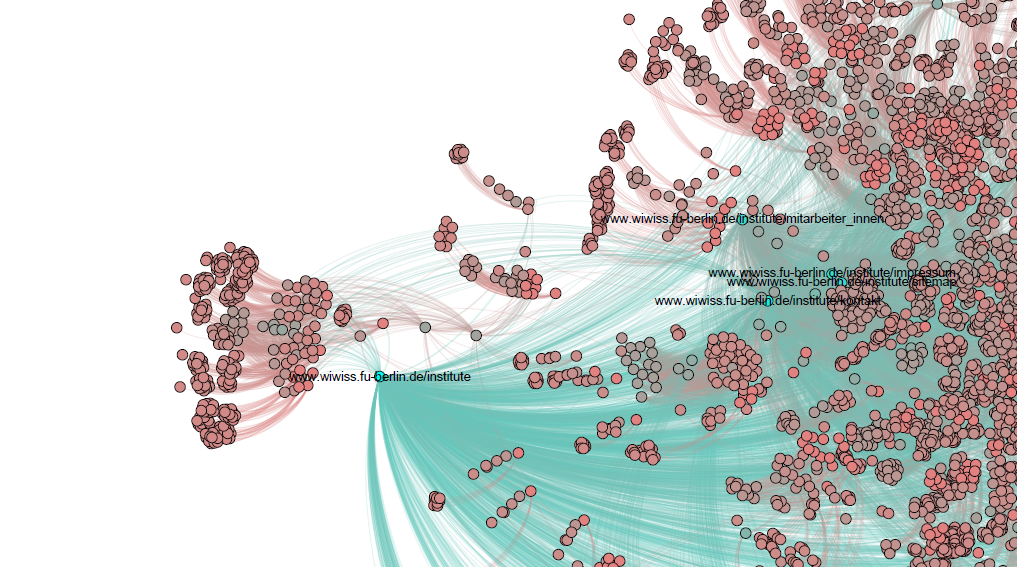
Um meine Studierenden dafür zu sensibilisieren und ihnen daneben auch noch ein paar schöne Netzwerkillustrationen zu zeigen, habe ich versucht einen Anwendungsfall zu finden, der sie direkt betrifft: Die Website unseres Fachbereiches. Wenn jede Website tendenziell interessante Informationen bereitstellt, ist es gar nicht so einfach zu bestimmen, welche Seite wahrscheinlich die interessanteste ist. Lernziele sind daher:
1. Zeige, wie wüst die Seitenlandschaft unseres Fachbereiches ist
2. Stelle dar, wie diese Seiten per Links zusammenhängen
3. Verdeutliche, wie das PageRank-System die „prominentesten“ Seiten findet
Das Ergebnis:
Ein Ausschnitt aus der Netzwerkgrafik des Fachbereiches Wirtschaftswissenschaft der Freien Universität BerlinEine Übersicht aus der Netzwerkgrafik der Website des Fachbereiches Wirtschaftswissenschaft der Freien Universität Berlin
Wie habe ich die Daten gewonnen und die Grafik erstellt?
Leider habe ich im Web keine fertige Datenbank gefunden, aus der ich direkt ein Netzwerk auslesen könnte. Ich musste es also selbst machen; am Beispiel unseres Fachbereiches.
Zunächst habe ich die Website (www.wiwiss.fu-berlin.de) gecrawlt. Unter Windows ist das etwas komplizierter als unter Linux, da hier keine einfachen Konsolenbefehle verwendbar waren. Mit WinHTTrack gab es aber auch eine schöne Drag&Drop-Lösung, mit der ich die Website zunächst offline bereit stellen konnte. (Grundsätzlich könnte man die Website auch direkt online analysieren. Ich trenne aber lieber Datensammlung und -auswertung)
Im nächsten Schritt habe ich die Website nach Links zu anderen Websiten der gleichen Domain durchsuchen lassen. Dafür habe ich ein Javascript geschrieben und serverseitig per NodeJS eingebunden. (Das Script stelle ich demnächst mal online) Dabei wurde jeweils der URI der aktuellen Seite als Source und der URI der verlinkten Seite als Target hinterlegt.
Mit dieser Liste aus Source:Target ergibt sich eine rudimentäre Edge-List mit unglaublich vielen Nodes, da jede Website als einzelne URI für Source bzw. Target angelegt wurde. Um diese Anzahl etwas zu reduzieren habe ich die *.html-Seiten per regulären Ausdrücken entfernt und rutsche damit auf dem Sitetree für jede Seite auf die darüber liegende Ebene. (Dafür habe ich Google Refine eingesetzt)
Um die Edge-List schließlich darzustellen, eignet sich das Netzwerkanalysetool Gephi hervorragend. Hier kann die Liste direkt eingeladen und bspw. per Force Atlas 2 Algorithmus dargestellt werden. Voilá! Und schon hat man eine Netzwerkgrafik einer tatsächlichen Website 😉
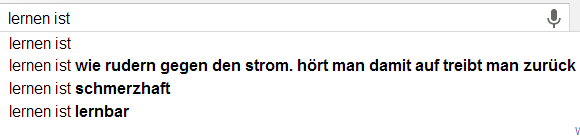
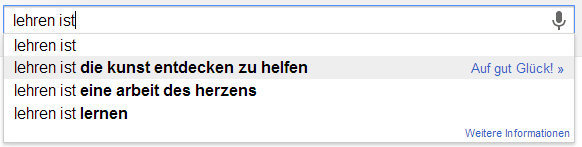
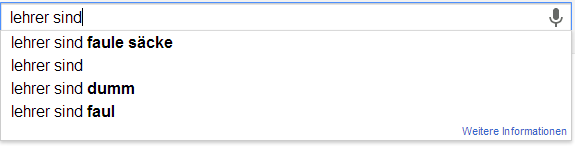
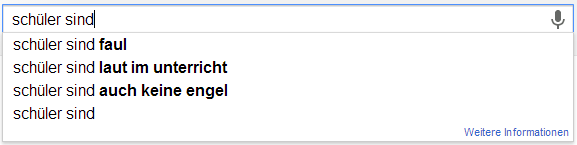
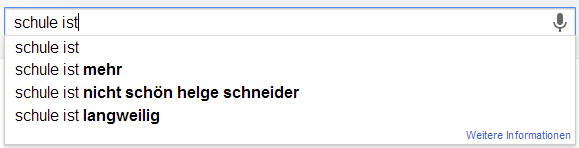
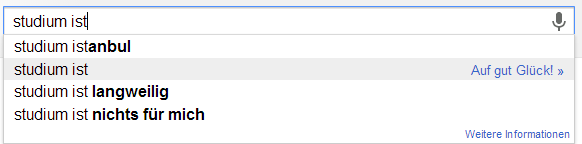
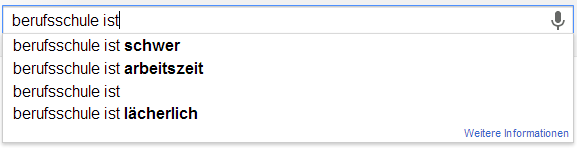
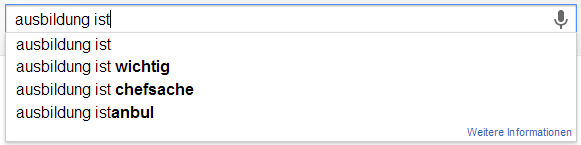
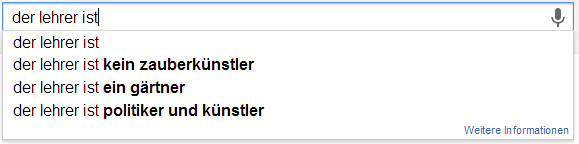
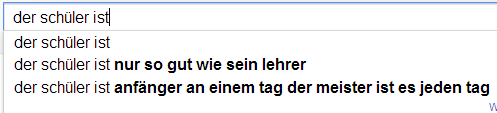
Ich möchte an der Stelle gerne das Experiment von Sandra Schön wiederholen. Sandra hat einfach verschiedene Begriffe rund um das Lehren und Lernen bei Google eingefügt. Die Auto-Vervollständigung von Google basiert ja auf den Suchanfragen aller Personen und wird entsprechend meiner History, meinen G+Beiträgen und all dem, was ich sonst so beim bunten Riesen mache, beeinflusst. Hier nun meine Ergebnisse um die Ergebnisse von Sandra zu objektivieren…
Abweichungen
Im direkten Vergleich kann ich die Ergebnisse von Sandra wohl weitestgehend wiederholen. Eine interessante Abweichung ist sicherlich, dass die Autovervollständigung bei „ist“ häufig auch „Istanbul“ schätzt. Das war bei ihr nicht der Fall. Darüber hinaus findet sich in etwa bei „Schüler sind“ eine abweichende Reihenfolge.
Kurzer semantischer Kommentar:
Scheinbar haben viele ex ante, also nach Abschluss von Schule/Studium, selten Grund nach dem Wort „Schule“ oder „Studium“ zu suchen. Das würde zumindest erklären, warum die ganze Verklärung von „Früher war doch alles so schön“ oder „Noch einmal studieren/in der Schule sein“ keinen großen Einfluss zu haben scheint. Ich würde daher vermuten, dass inbesondere aktuell Studierende bzw. derzeitige Schüler nach Begriffen suchen, die ihren Lebensbereich aktuell bestimmen. Wenn ich mich mit Schülern unterhalte (derzeit fast nie) oder mit Studierenden (derzeit fast ausschließlich) habe ich sehr häufig den Eindruck, dass die Kritikpunkte an der derzeitigen Lebenssituation und den bestimmenden Institutionen weit schwerer wiegen, als die Vorteile. Das ist insofern schade, als dass ich „gerne noch einmal (in Vollzeit) studieren würde“ 😉
Wir suchen Verstärkung – Es gibt 1.000 Euro Finderlohn!
Alles was Du tun musst, ist uns den Kontakt zu einem passenden Kandidaten für die Stelle des Redakteurs Webentwicklung (m/w) herzustellen. Wenn dein Kontakt der neue Redakteur (m/w) wird, bekommst Du 1.000 Euro als Belohnung. (aka)
I am not sure about his "rule of law" argument, but as a whole I agree with +Matt Cohler
concerning my difficulties about the "rule of law": Yes, Matt is right about the general perception and agreement of Germans with the law. Which gives a lot of security for investors. But sadly startups are rarely a key target for German law makers.
"Most crucially of all, Berlin is a place where there’s still no creative ecosystem holding the center stage. Berlin is one of the world’s great cities, but other than the German government Berlin isn’t really the global epicenter of anything…yet. And that’s the key reason I believe it’s the place in the Western world with the best shot at becoming a great new global tech startup ecosystem." – +Matt Cohler writing on +TechCrunch