In einer meiner Übungen erkläre ich den Studierenden, was es mit diesem Internet auf sich hat. Ich vertiefe darin unter anderem das Themengebiet Web 2.0 / Enterprise 2.0. Nebenbei sensibilisiere ich dann auch gleich für informatisch relevante Fragestellungen. Eine der interessantesten Fragen ist sicherlich: Wie finde ich eigentlich relevante Informationen?
Das ist gar nicht so einfach zu beantworten und darüber zerbrechen sich in einer Welt, in der Daten und Informationen einem potenziellen Wachstum unterlegen, viele Menschen den Kopf. Zwei dieser Köpfe waren die beiden Gründer von Google, Sergei Brin und Larry Page. Man mag über Google heute denken, was man mag, aber die Anwendung des PageRank-Algorithmus hat das Web revolutioniert.
Um meine Studierenden dafür zu sensibilisieren und ihnen daneben auch noch ein paar schöne Netzwerkillustrationen zu zeigen, habe ich versucht einen Anwendungsfall zu finden, der sie direkt betrifft: Die Website unseres Fachbereiches. Wenn jede Website tendenziell interessante Informationen bereitstellt, ist es gar nicht so einfach zu bestimmen, welche Seite wahrscheinlich die interessanteste ist. Lernziele sind daher:
1. Zeige, wie wüst die Seitenlandschaft unseres Fachbereiches ist
2. Stelle dar, wie diese Seiten per Links zusammenhängen
3. Verdeutliche, wie das PageRank-System die „prominentesten“ Seiten findet
Das Ergebnis:
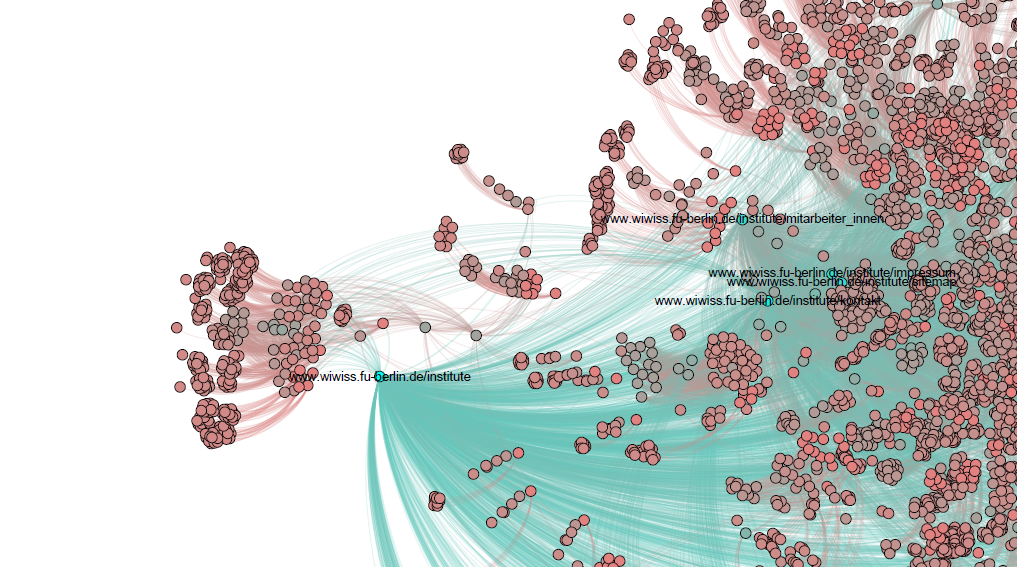

Die gesamte Netzwerkgrafik als PDF findet sich hier: 2013-06-30_wiwiss-website
Wie habe ich die Daten gewonnen und die Grafik erstellt?
Leider habe ich im Web keine fertige Datenbank gefunden, aus der ich direkt ein Netzwerk auslesen könnte. Ich musste es also selbst machen; am Beispiel unseres Fachbereiches.
- Zunächst habe ich die Website (www.wiwiss.fu-berlin.de) gecrawlt. Unter Windows ist das etwas komplizierter als unter Linux, da hier keine einfachen Konsolenbefehle verwendbar waren. Mit WinHTTrack gab es aber auch eine schöne Drag&Drop-Lösung, mit der ich die Website zunächst offline bereit stellen konnte. (Grundsätzlich könnte man die Website auch direkt online analysieren. Ich trenne aber lieber Datensammlung und -auswertung)
- Im nächsten Schritt habe ich die Website nach Links zu anderen Websiten der gleichen Domain durchsuchen lassen. Dafür habe ich ein Javascript geschrieben und serverseitig per NodeJS eingebunden. (Das Script stelle ich demnächst mal online) Dabei wurde jeweils der URI der aktuellen Seite als Source und der URI der verlinkten Seite als Target hinterlegt.
- Mit dieser Liste aus Source:Target ergibt sich eine rudimentäre Edge-List mit unglaublich vielen Nodes, da jede Website als einzelne URI für Source bzw. Target angelegt wurde. Um diese Anzahl etwas zu reduzieren habe ich die *.html-Seiten per regulären Ausdrücken entfernt und rutsche damit auf dem Sitetree für jede Seite auf die darüber liegende Ebene. (Dafür habe ich Google Refine eingesetzt)
- Um die Edge-List schließlich darzustellen, eignet sich das Netzwerkanalysetool Gephi hervorragend. Hier kann die Liste direkt eingeladen und bspw. per Force Atlas 2 Algorithmus dargestellt werden. Voilá! Und schon hat man eine Netzwerkgrafik einer tatsächlichen Website 😉